

اسپلانک(splunk) چیست؟
اسپلانک یک فناوری پیشرفته، مقیاسپذیر و مؤثر است که فایلهای گزارش ذخیره شده در یک سیستم را فهرستبندی و جستجو میکند. داده های تولید شده توسط ماشین را برای ارائه اطلاعات عملیاتی تجزیه و تحلیل می کند. مزیت اصلی استفاده از Splunk این است که برای ذخیره داده های خود ، به هیچ پایگاه داده ای نیاز ندارد، زیرا به طور گسترده از فهرست های خود برای ذخیره داده ها استفاده می کند.
Splunk نرمافزاری است که عمدتاً برای جستجو، نظارت و بررسی داده های بزرگ تولید شده توسط ماشین از طریق یک رابط گرافیکی به سبک وب استفاده میشود.
Splunk جمعآوری، نمایهسازی و ارتباط دادههای بلادرنگ را در یک ظرف قابل جستجو انجام میدهد که میتواند نمودارها، گزارشها، هشدارها، داشبوردها و تجسمها را از آن تولید کند. هدف آن ایجاد داده های تولید شده توسط ماشین در دسترس سازمان است و قادر به تشخیص الگوهای داده، تولید معیارها، تشخیص مشکلات و اعطای اطلاعات هوشمند برای اهداف عملیات تجاری است. Splunk یک فناوری است که برای مدیریت برنامهها، امنیت و انطباق، و همچنین تحلیلهای تجاری و وب استفاده میشود.
با کمک نرم افزار Splunk، جستجوی یک داده خاص در دسته ای از داده های پیچیده آسان است. همانطور که می دانید، در فایل های گزارش، تشخیص اینکه کدام پیکربندی در حال حاضر اجرا می شود، چالش برانگیز است. برای آسانتر کردن این کار، ابزاری در نرمافزار Splunk وجود دارد که به کاربر کمک میکند تا مشکلات فایل پیکربندی را شناسایی کند و پیکربندیهای فعلی که در حال استفاده است را ببیند.
چرا اسپلانک Splunk ؟
Splunk یک پلت فرم دیجیتالی است که به دسترسی به داده های تولید شده توسط ماشین کمک می کند، که برای همه مفید و ارزشمند خواهد بود. مدیریت حجم عظیمی از داده ها یکی از بزرگترین چالش ها است، زیرا توسعه سریعی در بخش فناوری اطلاعات و ماشین های آن وجود دارد. در این شرایط، Splunk نقش حیاتی برای مقابله با این وضعیت ایفا می کند.
راب داس و اریک سوان این فناوری را در سال 2003 به عنوان راه حلی برای تمام سوالات مطرح شده در حین بررسی غارهای اطلاعاتی که اکثر شرکت ها با آن مواجه بودند، پایه گذاری کردند. نام “اسپلانک” از کلمه “spelunking” گرفته شده است که به معنای کاوش در غارهای اطلاعاتی است. این به عنوان یک موتور جستجو برای فایلهای گزارشی که در زیرساخت یک سیستم ذخیره میشوند توسعه داده شد.
اولین نسخه Splunk در سال 2004 عرضه شد که تا حد زیادی مورد استقبال کاربران نهایی قرار گرفت. کم کم در بین اکثر شرکت ها شایع شد و شروع به خرید مجوزهای شرکت آن کردند. هدف اصلی بنیانگذاران این است که این فناوری در حال توسعه را به صورت انبوه به بازار عرضه کنند تا بتوان آن را تقریباً در تمام موارد استفاده ممکن به کار برد.
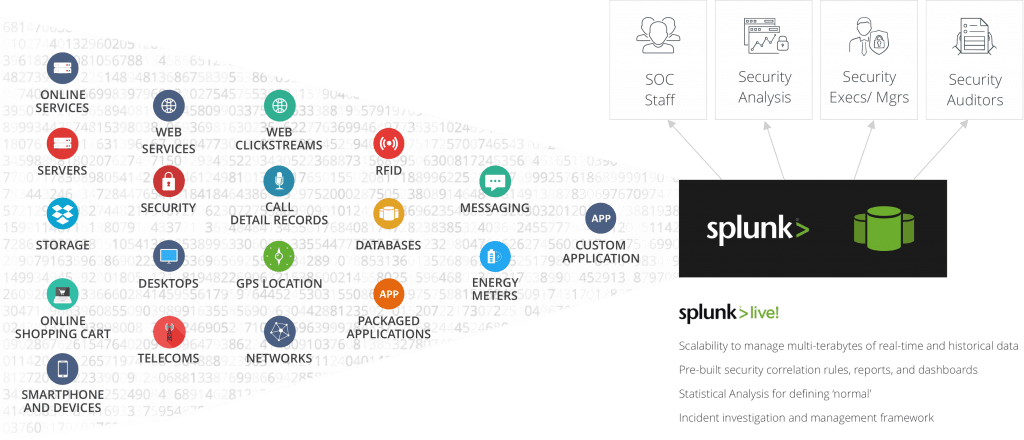
مزایای استفاده از Splunk
به گفته یکی از کاربران IT Central Station، برخی از ویژگیهای قابل توجه در مورد Splunk عبارتند از «عملکرد، مقیاسپذیری، و مهمتر از همه سبک نوآورانه جمعآوری و ارائه دادهها». از طرف دیگر، همان کاربر می نویسد که Splunk در تنظیم و افزودن منابع جدید می تواند پیچیده باشد.
در اینجا برخی از مزایای استفاده از Splunk وجود دارد:
- Splunk گزارش های تحلیلی را با نمودارها، نمودارها و جداول تعاملی ایجاد می کند و آنها را با دیگران به اشتراک می گذارد که برای کاربران مفید است.
- Splunk مقیاس پذیر و آسان برای پیاده سازی است.
- Splunk می تواند به طور خودکار اطلاعات مفیدی را که در داده های شما محصور شده است بیابد، بنابراین نیازی نیست خودتان آن را شناسایی کنید.
- این به ذخیره جستجوها و برچسبهای شما که به عنوان اطلاعات مهم شناخته میشوند کمک میکند تا بتواند سیستم شما را هوشمندتر کند.
حال بیایید در مورد اصطلاحات مربوط به معماری Splunk صحبت کنیم:
Universal Forwarder (UF):
یک عنصر سبک وزن است که به انتقال داده ها به فوروارد کننده سنگین Splunk کمک می کند. وظیفه اصلی این عنصر این است که فقط داده های گزارش را از سرور ارسال کند. شما به راحتی می توانید Universal Forward را در سمت مشتری یا در سمت برنامه نصب کنید.Load Balancer (LB):
در اصطلاح محاسباتی، Load balancing توزیع بارهای کاری را در منابع محاسباتی متعدد افزایش می دهد. متعادل کننده بار عنصری است که شبکه یا ترافیک برنامه را روی خوشه ای از سرورها توزیع می کند.Heavy Forwarder (HF):
به عنوان عنصر سنگین شناخته شده است. این کامپوننت Splunk شما را قادر می سازد تا داده ها را فیلتر کنید. به عنوان مثال، فقط به جمع آوری گزارش های خطا کمک می کند.Indexer:
وظیفه اصلی یک نمایه ساز ذخیره و نمایه سازی داده های فیلتر شده است. این به بهبود عملکرد Splunk کمک می کند. به طور پیش فرض، Splunk به طور خودکار نمایه سازی را مانند میزبان ها، منابع، تاریخ و زمان پیاده سازی می کند.سر جستجو (SH):
این به سادگی یک نمونه Splunk است که به توزیع جستجوها در نمایهسازهای دیگر کمک میکند، و معمولاً هیچ نمونهای از خود ندارد. اساساً برای دستیابی به اطلاعات و انجام گزارش استفاده می شود.Deployment Server (DS):
به استقرار پیکربندی مانند به روز رسانی فایل پیکربندی UF (جهت ارسال جهانی) کمک می کند. می توانید از DS برای به اشتراک گذاری داده ها بین اجزا استفاده کنید.License Master (LM):
یک مجوز Slave یک ایالت Splunk Enterprise است که توسط یک License Master کنترل می شود. اگر یک نمونه Splunk Enterprise دارید، به عنوان مدیر مجوز آن کمک می کند (زمانی که مجوز Enterprise را روی آن نصب کردید). مجوز بر اساس مقدار و استفاده است. به عنوان مثال، برای 50 گیگابایت استفاده در روز، Splunk جزئیات مجوز را روزانه بررسی می کند.
Forwarder:
به جمعآوری دادهها از ماشینهای اولیه کمک میکند، سپس دادهها را در زمان واقعی به نمایهساز ارسال میکند.Indexer:
به پردازش داده های دریافتی در زمان واقعی کمک می کند. همچنین داده ها را روی دیسک جمع آوری و مرتب می کند.سر جستجو:
با کمک Search Head، کاربران نهایی می توانند با Splunk تعامل داشته باشند. این به کاربران امکان می دهد تا عملکردهای جستجو، تجزیه و تحلیل و تجسم را انجام دهند.
اکنون بیایید به طور مفصل ببینیم که معماری Splunk چگونه کار می کند:
- ارسال کننده می تواند داده ها را ردیابی کند، یک کپی از داده ها تهیه کند و می تواند قبل از ارسال آن به فهرست کننده، تعادل بار را روی آن داده خاص انجام دهد.
- شبیهسازی میتواند به تولید کپیهای تکراری از هر مورد در منبع داده کمک کند، در حالی که متعادلسازی بار انجام میشود تا حتی اگر یک مورد از بین برود، آن دادهها را میتوان به کیس دیگری که میزبان فهرستکننده است منتقل کرد.
- هنگامی که داده ها از فورواردکننده به دست می آیند، سپس در یک جزء Indexer رها می شوند. در Indexer، دادههای بهدستآمده به دادههای منطقی مختلف تقسیم میشوند و در هر ذخیرهگاه داده، میتوانید مقاماتی را تنظیم کنید که سپس دیدگاهها و دسترسیهای کاربر را هدایت میکنند.
- وقتی دادهها در Indexer هستند، میتوانید آن دادهها را کاوش کنید و آن کاوشها را به همراهان جستجوی مختلف اختصاص دهید و همه نتایجی که پس از تخصیص به دست میآوریم ادغام شده و به سر جستجو منتقل میشوند.
- همچنین میتوانید زمانبندی همراهان جستجو و ایجاد هشدارها را انجام دهید، که سپس زمانی فعال میشوند که برخی موقعیتها با جستجوهای ذخیرهشده مطابقت داشته باشند.
- همچنین می توانید از اشیاء دانش فقط برای تشدید داده های بدون ساختار موجود (داده هایی که هیچ قالبی ندارند) استفاده کنید.
- سرهای جستجو و اشیاء دانش را می توان از یک Splunk CLI یا یک Splunk Web Interface بازیابی کرد. این تعامل از طریق یک اتصال REST API رخ می دهد.